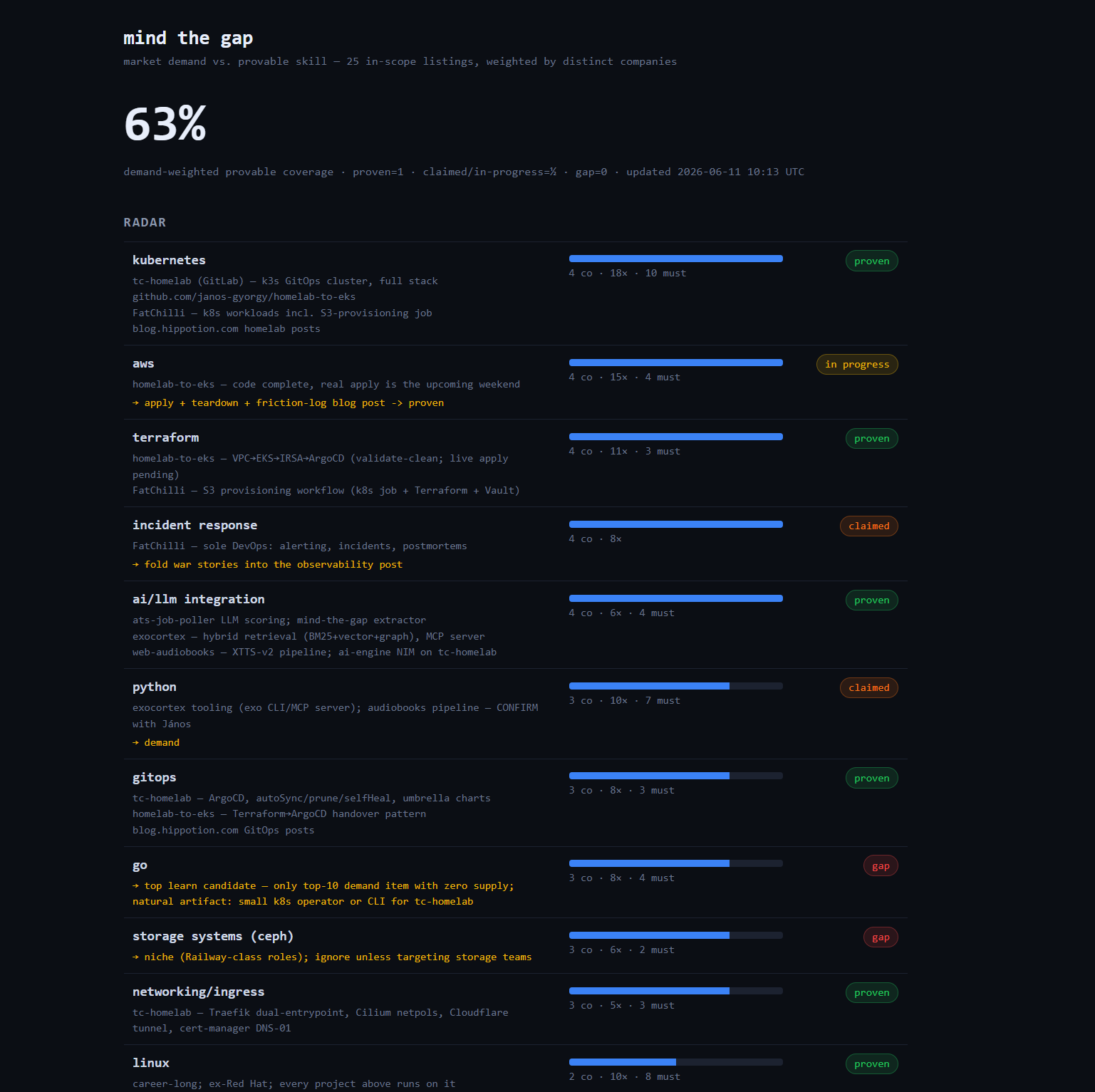
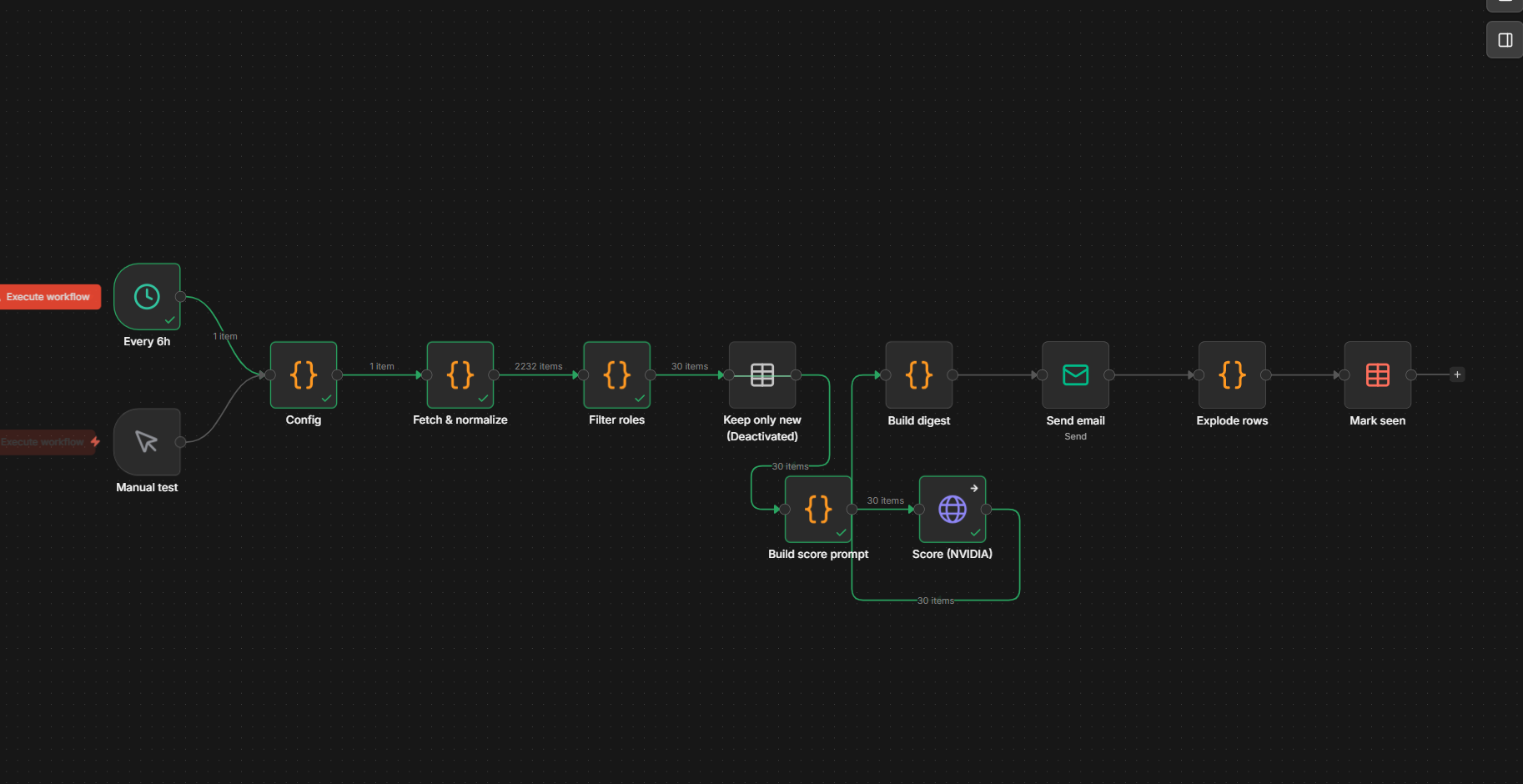
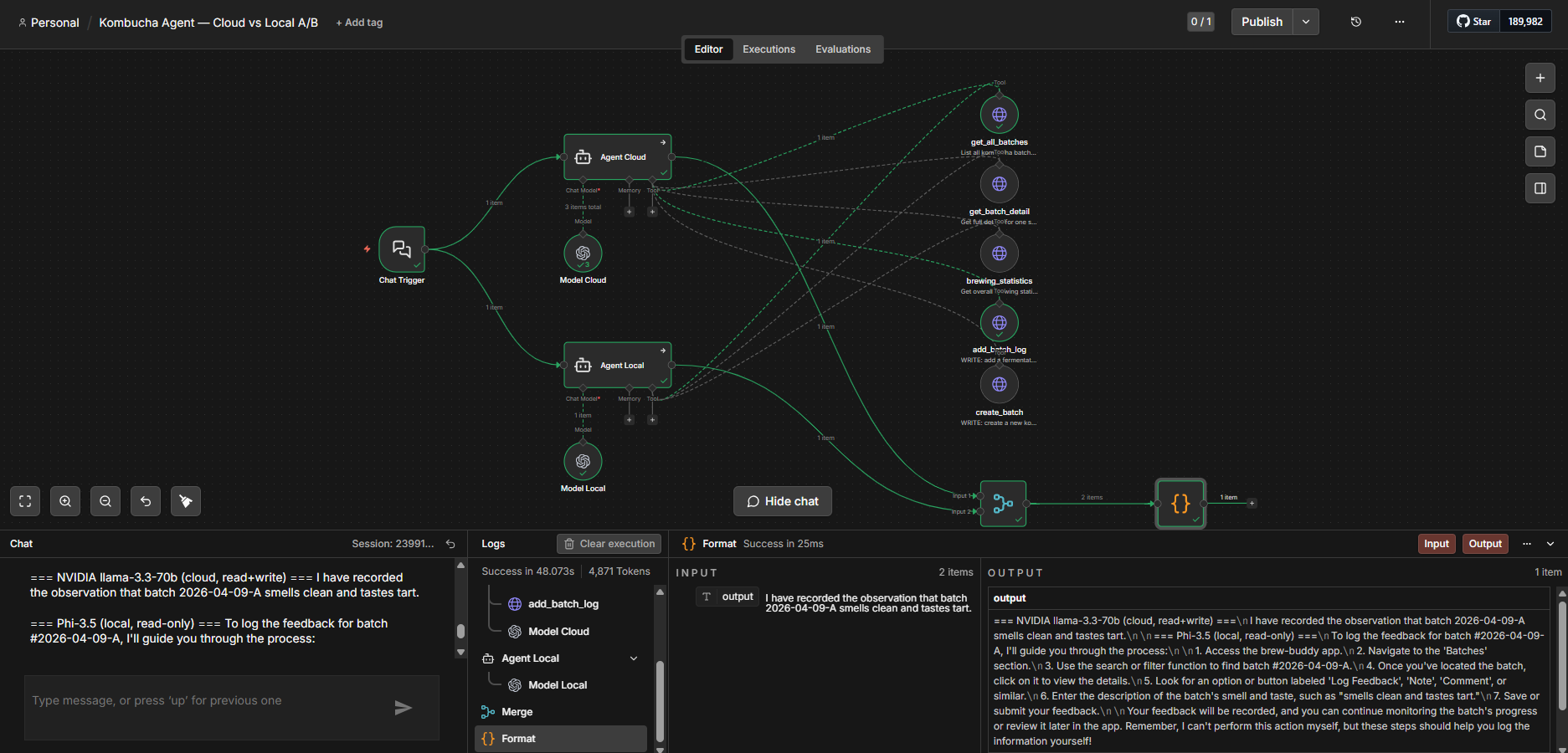
VoteWatch: How Your Representatives Voted — and Whether You'd Agree
Parliamentary roll-call votes are public, machine-readable, and almost completely unread. I built a thing that scrapes them, distills each decision into one plain-language question, shows which party voted which way, and lets you register whether you agree — then puts your answer next to how parliament actually voted. The rule that keeps it honest: the AI writes the summary, but it never decides a fact.