
📝 Dev Notes
Running notes on things I’ve hit, fixed, or found worth remembering.
Running notes on things I’ve hit, fixed, or found worth remembering.

My house is full of automation that never told me anything — until I gave it one push bus. The first thing I taught it to do was warn me before Claude Code cuts out mid-task.

I set out to answer a simple worry — is someone trying to get into my server? — and found the scarier question underneath it: if they did, would I even know? My front door was solid. The inside had an alarm with the wires cut, a web terminal sitting on the open internet, and no floor under the blast radius. Here’s the audit, and the three things I fixed.
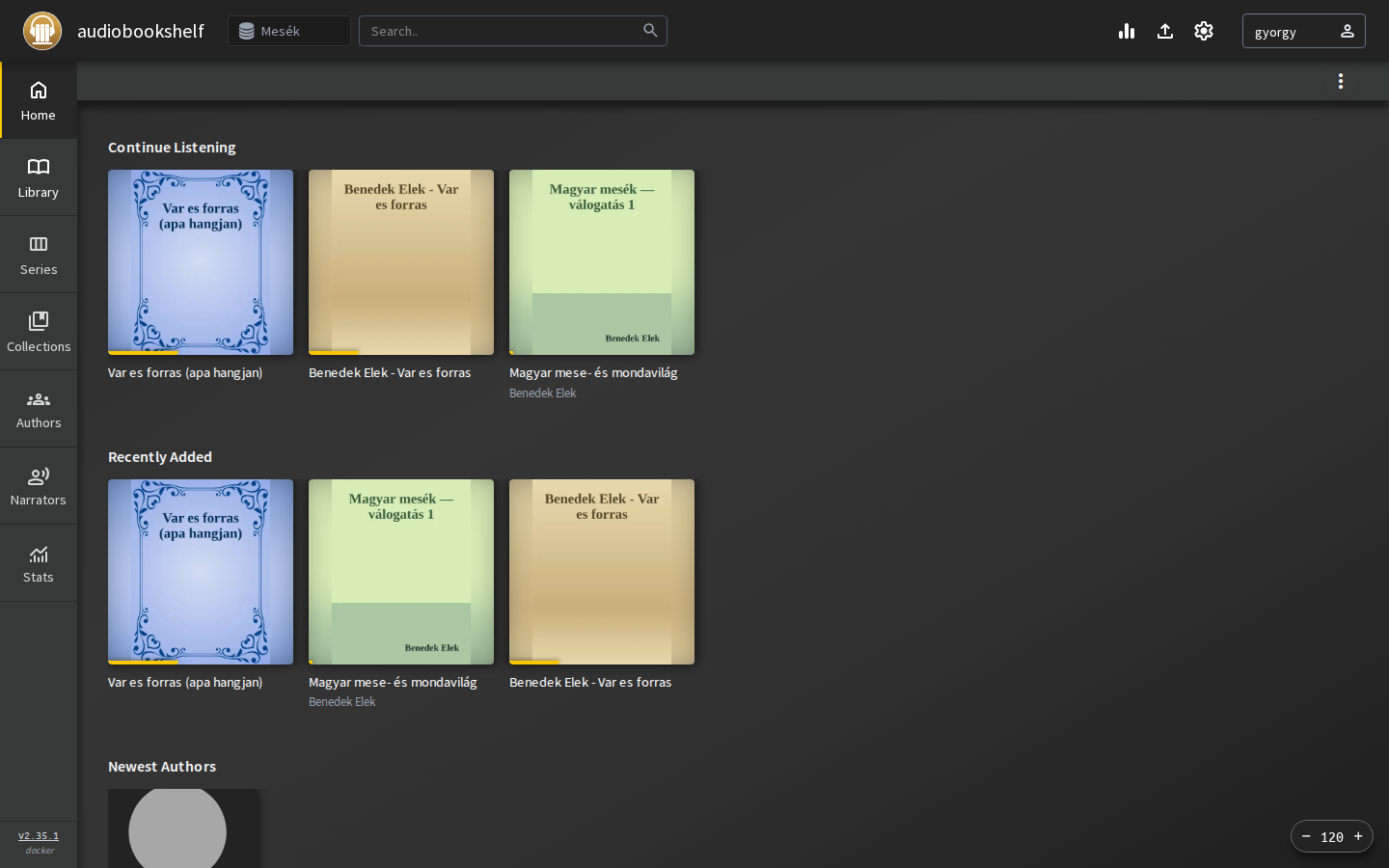
Zero-shot voice cloning with XTTS-v2 on a CPU-only k3s node: 26 seconds of phone audio in, a cloned-voice audiobook out — and an honest verdict from the bedtime jury. Every manual step, including the ones that went wrong.
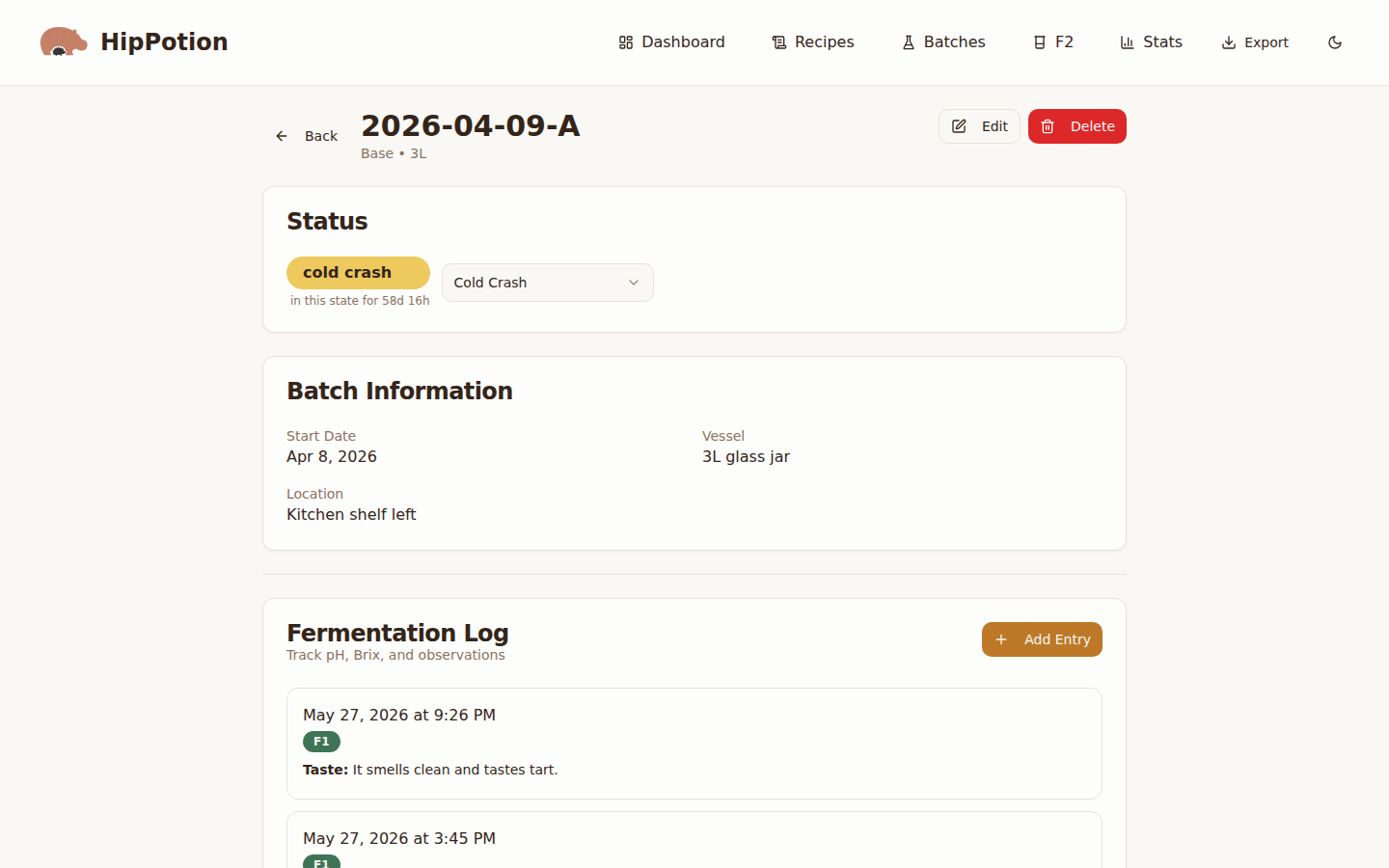
Brewing kombucha looks simple until you try to model it: one batch splits into many flavored bottles, every jar generates a stream of pH and taste readings, and a SCOBY has a lineage. Here’s the little app I built to keep track — and why the schema, not the code, was the real work.
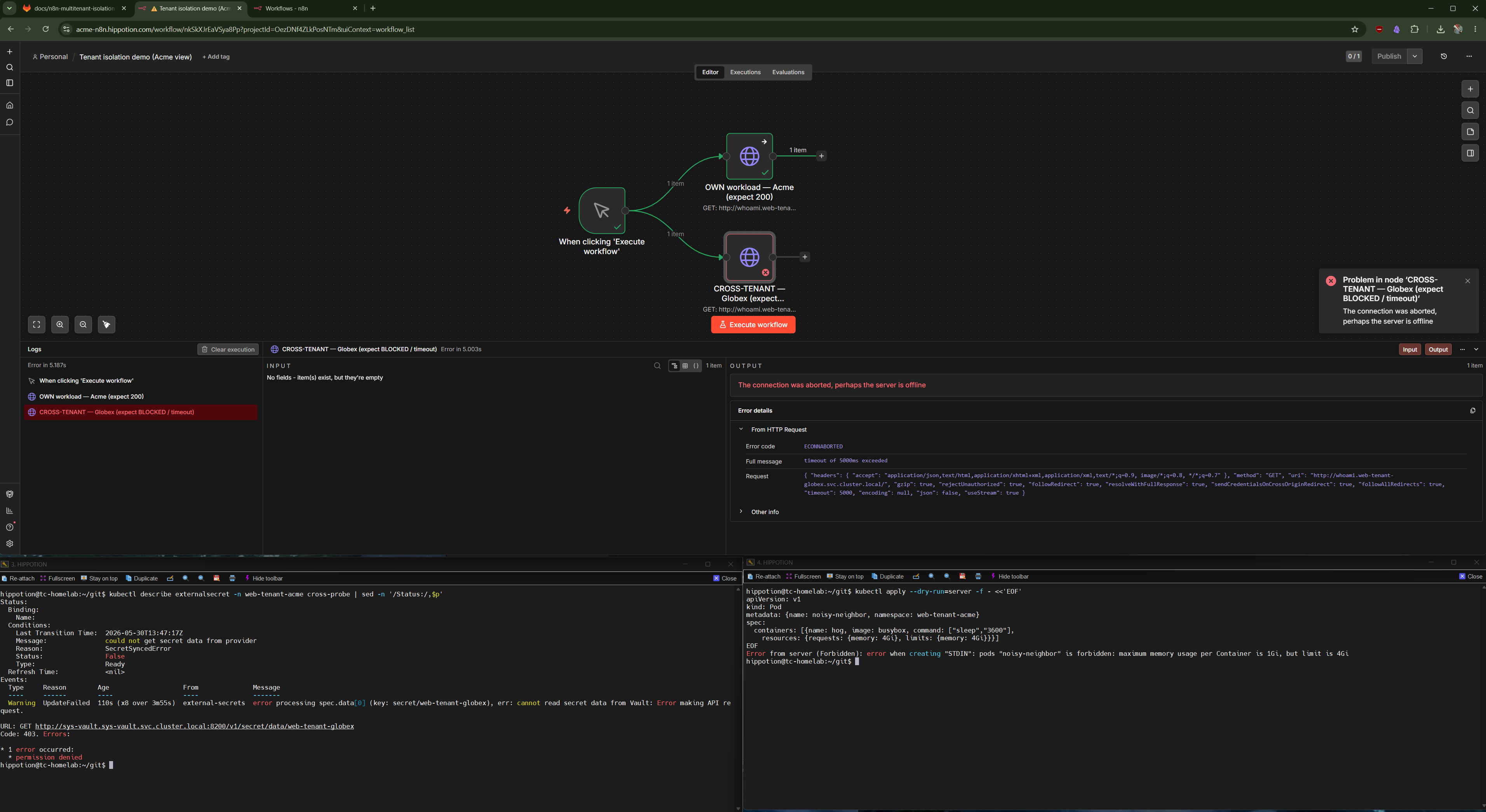
Multi-tenant isolation is easy to assert and hard to verify. Three walls — network, secret, resource — and the actual 403s, timeouts, and admission rejections that prove each one holds.
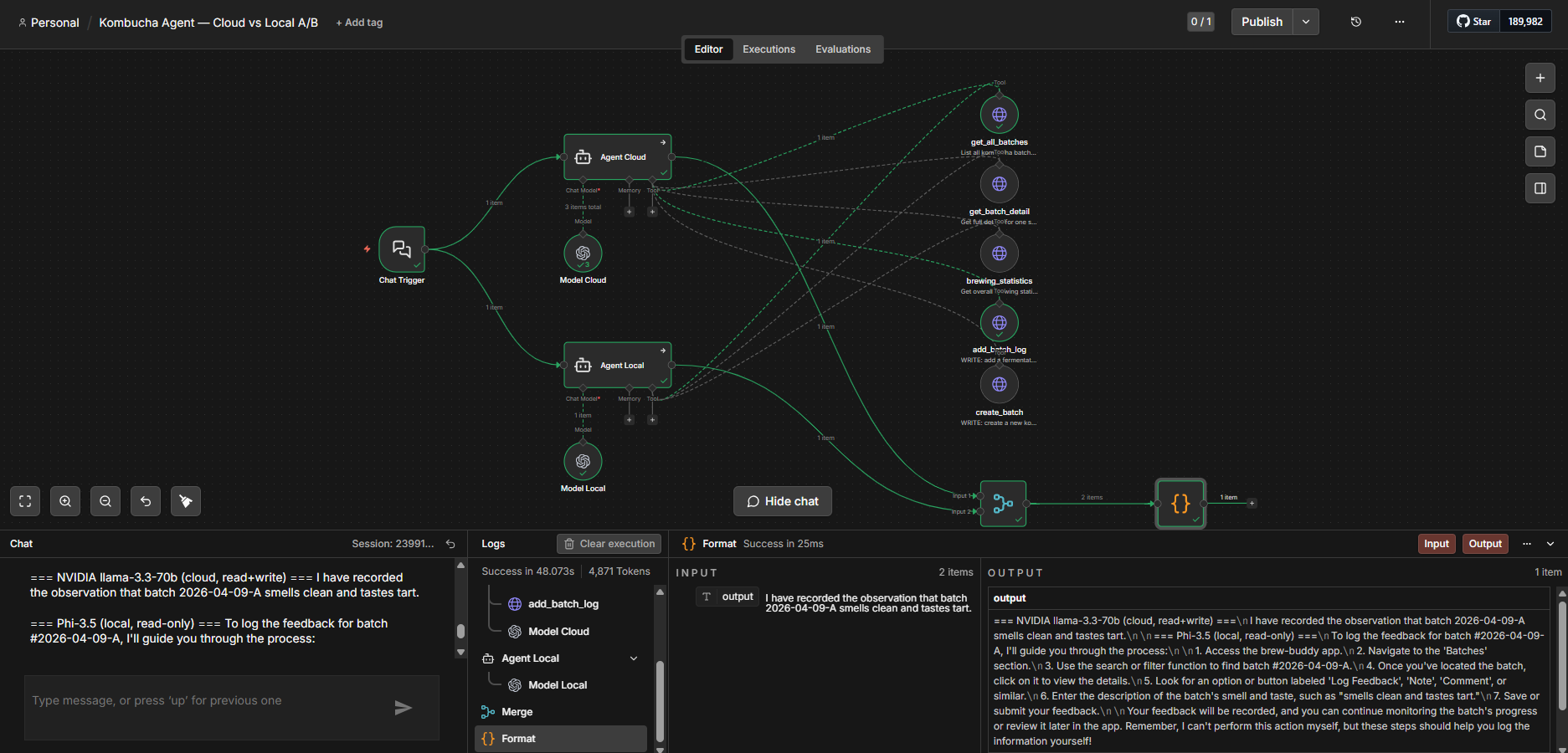
I built an AI agent in self-hosted n8n over my kombucha-tracking app, then gave it two brains — NVIDIA’s 70B and a local Phi-3.5 — sharing the same tools. The cloud model called the tools and answered from real data. The local one couldn’t, so it made things up.

Raw YAML, Kustomize, Helm, Jsonnet — there’s more than one way to describe what you want running in a cluster. Here’s what each actually looks like in practice and where each one breaks.
A local model classifies every prompt before it leaves the cluster. If it’s sensitive, it’s blocked. If it’s clean, it goes to NVIDIA NIM. 150 lines of FastAPI, deployed on k3s.

Replace PII with semantically realistic fakes before sending to a cloud LLM, then restore the originals from the response. Started with a general model and prompt engineering — then upgraded to a purpose-built 1.7B fine-tune via Ollama.