🎯 Know the Market Without Job-Hunting: An LLM-Scored Job Poller in n8n
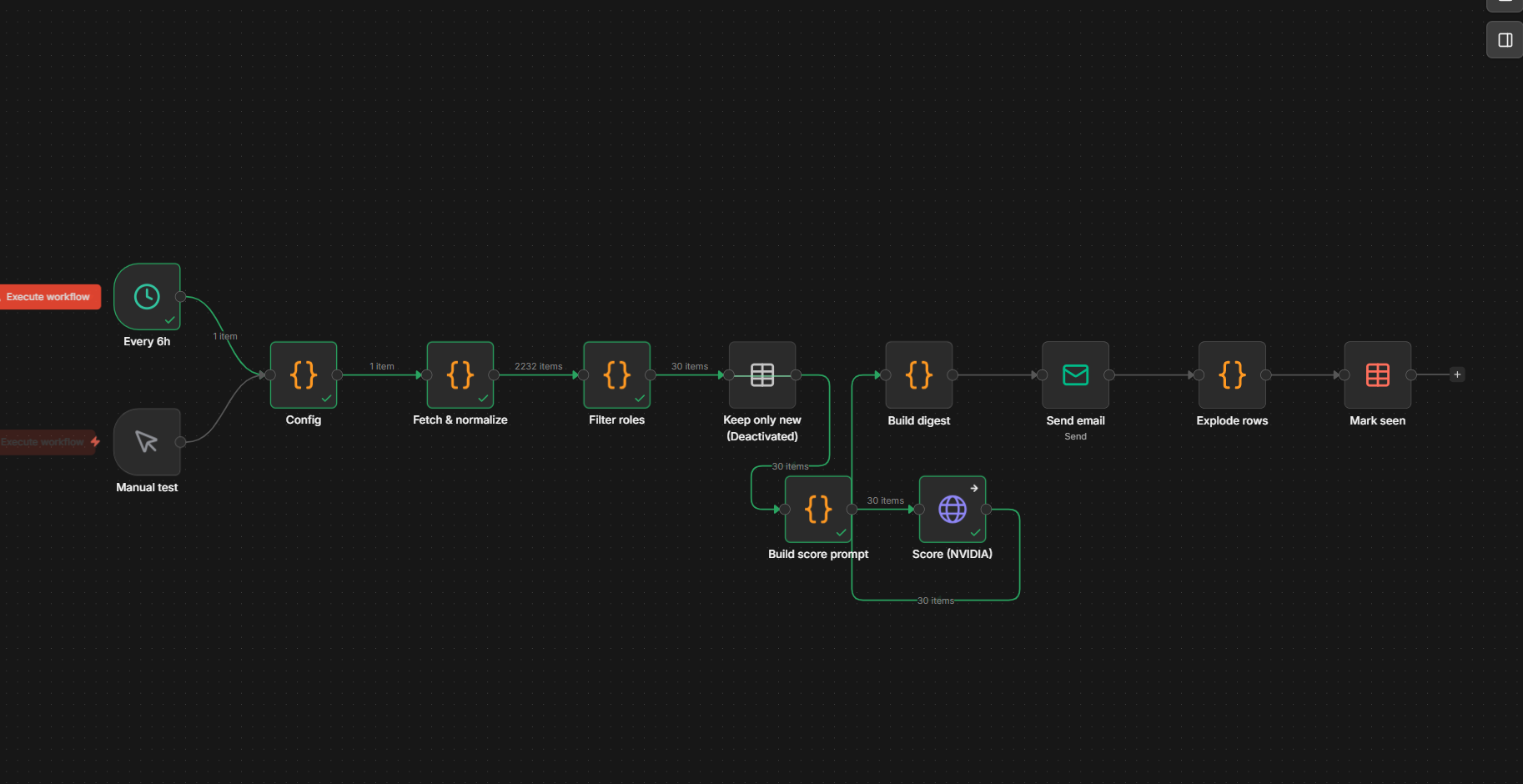
You don’t have to be job-hunting to want to know your market — what’s out there, what it pays, where you’d fit. So I built an n8n workflow: it polls the public ATS APIs (Greenhouse/Lever/Ashby) plus a broad remote-jobs feed, filters for remote-EU infra roles, scores each posting against my CV with an LLM, and emails me only the 80%+ matches. No database, no scraping.