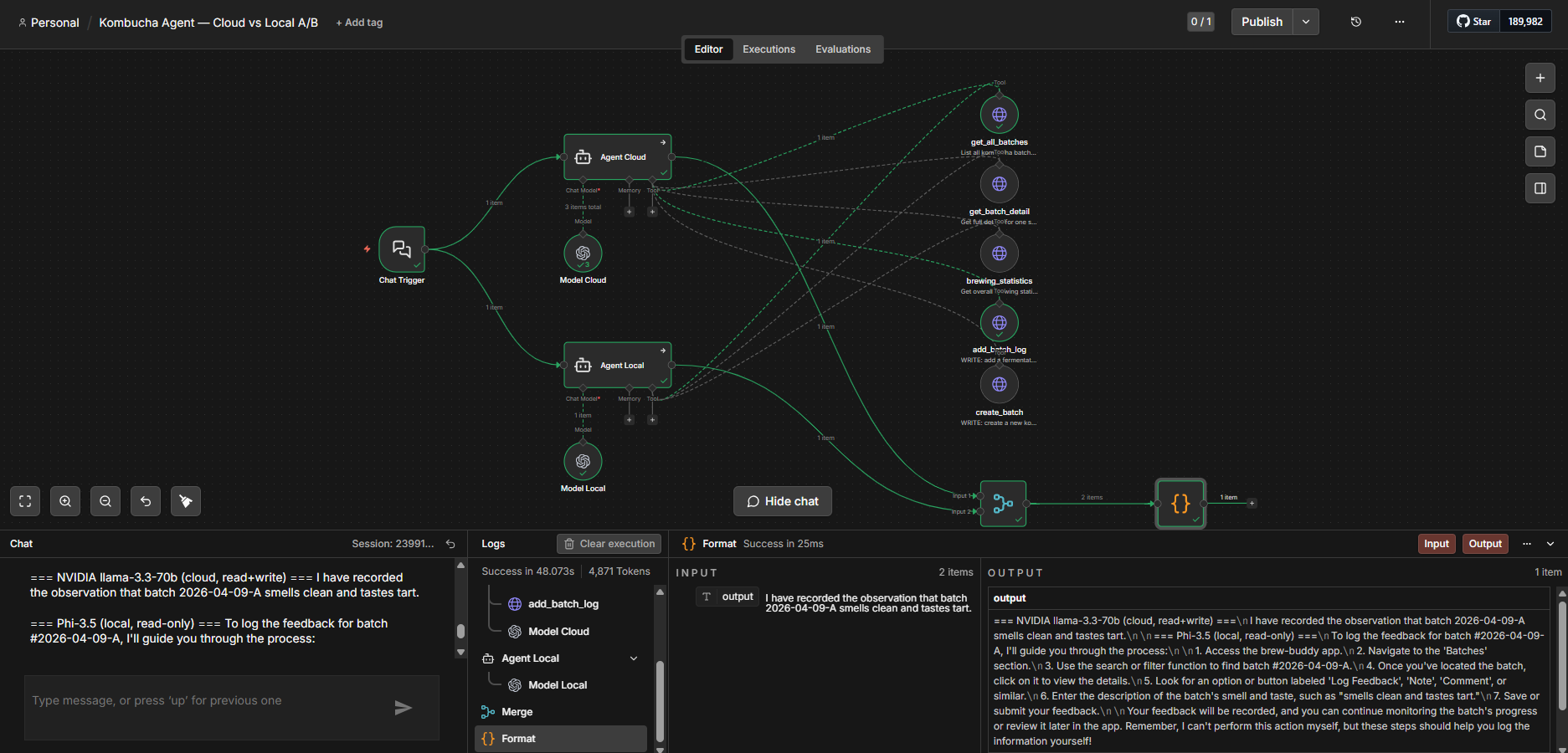
🍵 I A/B-Tested Cloud vs Local LLMs in One n8n Agent. The Local One Faked It.
I built an AI agent in self-hosted n8n over my kombucha-tracking app, then gave it two brains — NVIDIA’s 70B and a local Phi-3.5 — sharing the same tools. The cloud model called the tools and answered from real data. The local one couldn’t, so it made things up.