
🦛 What Is Hippotion
A name that works in two languages, hides two animals, and started as a kombucha label.
A name that works in two languages, hides two animals, and started as a kombucha label.

Raw YAML, Kustomize, Helm, Jsonnet — there’s more than one way to describe what you want running in a cluster. Here’s what each actually looks like in practice and where each one breaks.
A local model classifies every prompt before it leaves the cluster. If it’s sensitive, it’s blocked. If it’s clean, it goes to NVIDIA NIM. 150 lines of FastAPI, deployed on k3s.

Replace PII with semantically realistic fakes before sending to a cloud LLM, then restore the originals from the response. Started with a general model and prompt engineering — then upgraded to a purpose-built 1.7B fine-tune via Ollama.

llama.cpp’s inference server ships a /metrics endpoint. One flag, Prometheus scraping, a Grafana dashboard loaded via ConfigMap sidecar — AI observability without a proxy layer.

A CPU-only self-hosted LLM stack running on k3s: llama.cpp as the inference server, Open WebUI as the chat interface, deployed as a single Git push.

Rebooting a misbehaving node feels productive. It isn’t. You’re erasing your evidence and skipping the lesson.
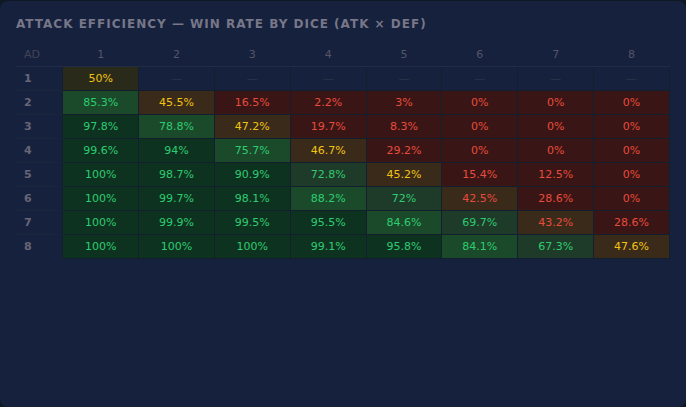
Building a telemetry backend for Dice & Shrines — every attack logged, every guardian tracked, every die rolled accounted for. What the data revealed about balance, luck, and how people actually play.
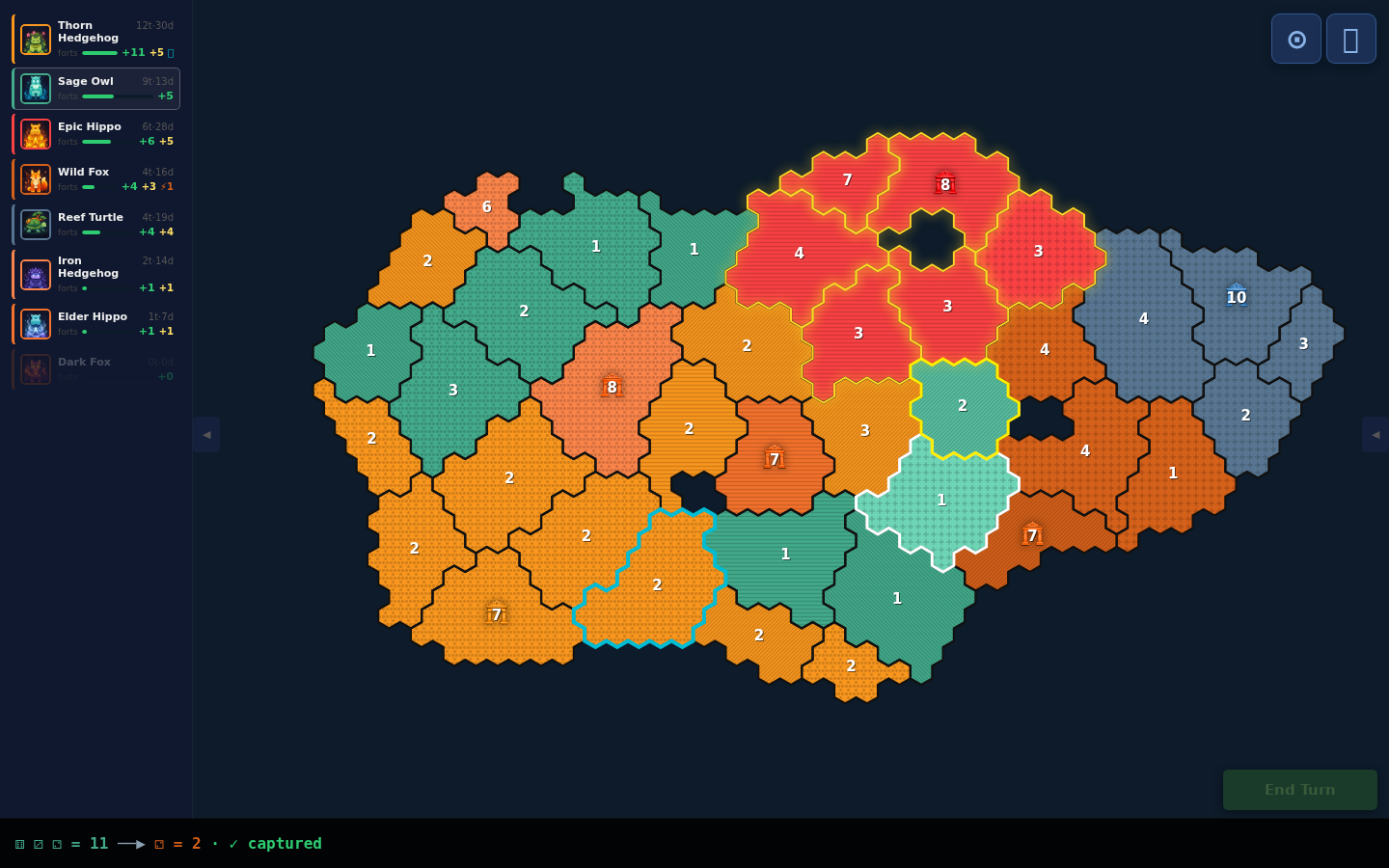
What started as a Claude Code / Codex sandbox became a territory conquest game with five asymmetric guardians, procedurally generated hex maps, and a stats service to balance them. Here’s what happened.

Kubernetes rolling updates don’t give you zero-downtime for free. There are four separate things you have to get right, and most clusters get at least one wrong.