The question
“You’re running n8n for multiple customers on the same Kubernetes cluster. What stops Customer A from reading Customer B’s API keys, calling Customer B’s services, or starving Customer B’s workflows by burning the whole node?”
Three different walls, three different mechanisms. Most articles I’ve read on K8s multi-tenancy list the primitives — namespaces, NetworkPolicies, ResourceQuotas, RBAC — without showing what each one actually catches when you try to cross it. This post does the second part. The receipts are the point.
The setup: two namespaces, web-tenant-acme and web-tenant-globex, each running their own n8n instance on the same node. The only thing keeping them apart is the walls we build around each namespace.
The mental model: subtractive isolation
Kubernetes is a flat network with shared everything by default. You don’t add isolation by writing allow rules. You subtract trust by adding default-deny rules, and then carefully allow back only the connections each tenant actually needs.
A tenant doesn’t have access to another tenant because there is no rule allowing it. The absence of an allow rule is the wall.
Three of these absences make up the picture:
| Wall | Primitive | Failure mode when crossed |
|---|---|---|
| Network | Cilium NetworkPolicy, default-deny egress | Connection times out (silent drop) |
| Secret | Vault Kubernetes-auth, per-tenant policy | 403 permission denied from Vault itself |
| Resource | ResourceQuota + LimitRange | Pod rejected at admission time |
Different layers, different error messages. That’s how you can tell what stopped you.
Wall 1 — Network: Cilium NetworkPolicy
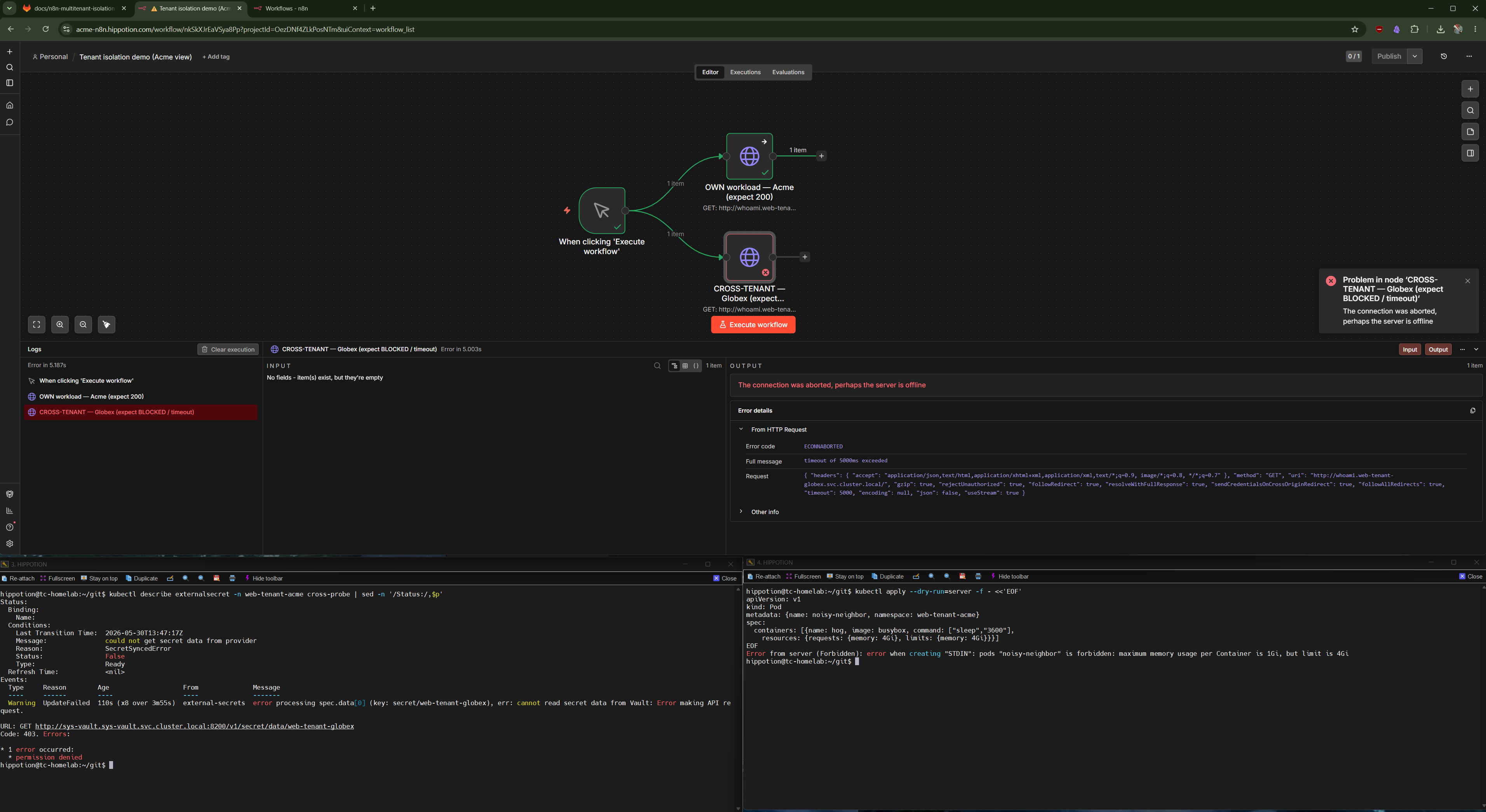
n8n in web-tenant-acme can reach whoami.web-tenant-acme.svc.cluster.local (its own service in its own namespace) but not whoami.web-tenant-globex.svc.cluster.local. The same DNS shape, the same cluster, the same node. One succeeds, the other hangs.
The primitive is a default-deny egress policy applied to every pod in the namespace, with two narrow exceptions: intra-namespace traffic (so n8n can still reach its own service) and DNS to kube-system (otherwise nothing resolves anything).
# Effective policy on every pod in web-tenant-acme:
spec:
podSelector: {}
policyTypes: [Egress, Ingress]
egress:
- to: # intra-namespace traffic OK
- podSelector: {}
- to: # DNS to kube-dns OK
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: kube-system
ports: [{port: 53, protocol: UDP}]
There is no rule for web-tenant-globex. Cilium’s eBPF datapath drops the SYN packet on the way out.
The receipt — an n8n HTTP node configured to GET http://whoami.web-tenant-globex.svc.cluster.local/. It hangs for the full timeout, then errors with AxiosError: timeout of 5000ms exceeded / code: ECONNABORTED.
The interesting bit: DNS still works. kube-dns is allowed, so the cross-namespace Service still resolves. The TCP handshake is what gets dropped. That’s a useful signal in real incident response — “DNS resolves but the connection hangs” almost always means a NetworkPolicy is the cause.
Wall 2 — Secret: Vault Kubernetes-auth + ESO
Now imagine Acme’s n8n misbehaves: somebody pushes a workflow that tries to read Globex’s API keys via an ExternalSecret. The network isn’t the issue — both tenants need to reach Vault, so they both have an egress rule for sys-vault. The wall has to be at the identity layer.
Each tenant gets three things:
- A dedicated
ServiceAccount(n8n-acme,n8n-globex). - A Vault Kubernetes-auth
rolebound to that SA in that namespace, mapped to a Vaultpolicythat grantsreadon only its own KV path. - A namespaced External Secrets
SecretStorethat authenticates as the SA via the Kubernetes TokenRequest API.
# Vault policy: tenant-acme can read its own secrets, nothing else.
path "secret/data/web-tenant-acme" { capabilities = ["read"] }
path "secret/metadata/web-tenant-acme" { capabilities = ["read"] }
vault write auth/kubernetes/role/tenant-acme \
bound_service_account_names=n8n-acme \
bound_service_account_namespaces=web-tenant-acme \
policies=tenant-acme \
ttl=1h
When Acme’s n8n tries an ExternalSecret pointing at secret/web-tenant-globex/..., ESO authenticates fine (the SA is valid), Vault recognises the caller, looks up the tenant-acme policy, and answers with the most satisfying line in this whole demo:
URL: GET http://sys-vault.sys-vault.svc.cluster.local:8200/v1/secret/data/web-tenant-globex
Code: 403. Errors:
* permission denied
This is the bit that separates “namespace isolation” from real multi-tenant secret isolation. Plain Kubernetes Secrets + RBAC stop a tenant from listing another tenant’s Secret objects, but the moment you go upstream — to Vault, to a cloud KMS, to an SSM Parameter Store — the secret store needs to enforce identity itself. The network said yes; the secret store still says no.
Wall 3 — Resource: ResourceQuota + LimitRange
The third concern is the noisy neighbour: Acme’s runaway workflow allocating a 4Gi pod and OOM-killing everything else on the node. The network policy doesn’t catch this (no network call), and Vault doesn’t catch this (no secret request). The kernel will, eventually — but you don’t want eventually. You want admission-time rejection.
Two primitives:
apiVersion: v1
kind: ResourceQuota
metadata: { name: tenant-quota, namespace: web-tenant-acme }
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
pods: "10"
---
apiVersion: v1
kind: LimitRange
metadata: { name: tenant-limits, namespace: web-tenant-acme }
spec:
limits:
- type: Container
default: { cpu: 500m, memory: 512Mi }
defaultRequest: { cpu: 50m, memory: 128Mi }
max: { cpu: "2", memory: 1Gi }
ResourceQuota caps the namespace total. LimitRange bounds any individual container and supplies defaults so pods that don’t declare requests/limits still get reasonable ones — important because a missing limit on a single container can blow past the quota in one allocation.
The receipt — a server-side dry-run of a single 4Gi pod, which never gets created:
$ kubectl apply -n web-tenant-acme --dry-run=server -f noisy-neighbor.yaml
Error from server (Forbidden): error when creating "STDIN":
pods "noisy-neighbor" is forbidden:
maximum memory usage per Container is 1Gi, but limit is 4Gi
Not a kernel OOMKill. Not a pod stuck in Pending. A flat refusal from the API server before the scheduler even sees the request.
What this does not prove
A homelab demo on one node with two synthetic tenants is not n8n Cloud. The honest gaps:
- Execution sandboxing. A workflow can still run arbitrary code via the
Codenode or shell-outs. These walls stop infrastructure leakage; they don’t sandbox what n8n itself executes. Real n8n Cloud needs more than namespace walls for that — gVisor / Firecracker / per-tenant worker pools are the usual answers, and n8n’s queue mode lends itself to the last. - Pooled worker queues. Queue mode runs main/webhook/worker as separate deployments backed by Redis + Postgres. Two tenants sharing a worker pool need additional checks at the job-routing layer to keep workflows from accessing the wrong tenant’s binary data. Out of scope for the homelab demo.
- Control plane. Both tenants reach the same API server. A cluster-admin-equivalent compromise breaks everything. This is the assumption every shared K8s setup makes.
- Node-level. Same kernel. Container escape, CPU side channels, the usual list — all apply. For paranoid tenants the answer is dedicated nodes via taints/tolerations or separate clusters entirely.
The demo proves the namespace-shaped walls hold. It does not prove the whole stack is safe against a determined attacker already running code inside a tenant. That’s a different post.
Part of a Kubernetes-on-the-homelab series — previously: preventing a compromised pod from calling your database, GitOps secrets.