The question
I run n8n on my k3s homelab. Not docker-compose on a NUC — the full treatment: GitOps-reconciled, Vault-backed secrets, default-deny networking. The same boring platform everything else here runs on.
But “I have n8n running” proves nothing. I wanted to know if I actually understood it as an agent platform, and to answer a question I kept dodging: for agent work, do I need a cloud model, or is my local one good enough?
So I built a real agent and gave it two brains.
What I built
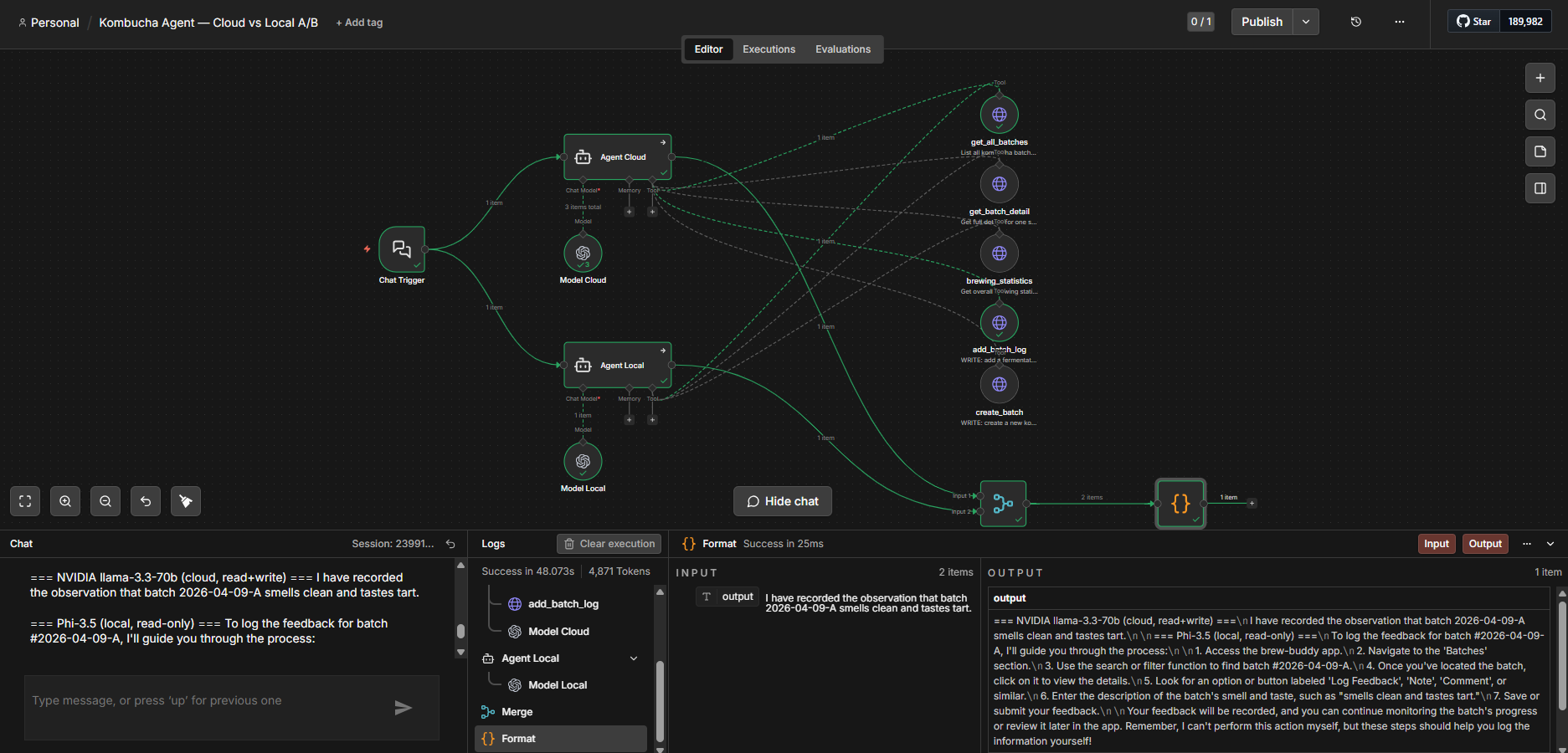
A chat assistant over brew-buddy, my homemade kombucha-tracking app (React + a small API + Postgres). You ask it things in plain language; it calls the app’s API and answers. The twist: the same question runs through two agents in parallel — one backed by NVIDIA’s hosted Llama-3.3-70B, one by a local Phi-3.5-mini on CPU — and the workflow prints both answers side by side.
Chat ──▶ Agent (cloud: NVIDIA 70B) ──┐ tools (shared):
└─▶ Agent (local: Phi-3.5) ──┤ • get_all_batches
│ • get_batch_detail
│ • brewing_statistics
(Merge) ──▶ both replies, labeled • add_batch_log ⟵ write
• create_batch ⟵ write
Both agents share the same read tools. The two write tools are wired to the cloud agent only — more on that below.

The nice part: I didn’t write a line of glue. n8n’s stock OpenAI Chat Model node talks to anything OpenAI-compatible if you override the credential’s Base URL — so one node points at https://integrate.api.nvidia.com/v1, the other at http://llama-server.<ns>.svc:8080/v1 for the local server. Same node, two endpoints.
The infra that keeps it honest
I won’t re-explain the platform here — it’s in earlier posts: GitOps, Vault-backed secrets, default-deny networking, dual-path TLS ingress. But building the agent made one of them tangible.
n8n is, by design, a thing that makes arbitrary HTTP calls on a schedule. That’s exactly what you want behind a default-deny network policy. n8n couldn’t reach the brew-buddy API at all until I declared it — one line:
# n8n's namespace
allowEgressToNamespaces: [web-ai-engine, web-brew-buddy]
# ^ added this for the agent
(plus a matching ingress-allow on brew-buddy’s side). That’s the posture working as intended: the blast radius of a workflow tool is whatever I’ve explicitly granted, and not one namespace more. Adding a capability is a reviewable one-liner in Git; Argo reconciles it. No kubectl, no guessing what n8n can reach.
The A/B: same agent, same tools, two brains
Plain “hi”. Cloud answers in ~0.5s. Local takes noticeably longer — because even for “hi”, the agent feeds the model the full system prompt plus the JSON schemas for every tool, and Phi-3.5 has to chew through all of it on CPU before it can say a word. So far, the boring expected result: local is slower.
Then I asked a real question, and the result flipped in a way I didn’t expect.
“What batches do I have?”
Cloud (70B) called get_all_batches, got the real rows, and answered:
You have two batches: 2026-04-09-A (cold-crash, 3L) and 2026-04-09-W (cold-crash, 3L).
Local (Phi-3.5) never called the tool. It didn’t seem to realise it had tools. Instead it confidently explained how I could go find the data myself:
To list all batches: 1. Access the brew-buddy app. 2. Look for a button labeled “List Batches”…
def get_all_batches(): …… Remember, I’m unable to directly interact with apps or databases.
Fake instructions. Fake code. A polite apology. Everything except the actual answer it was sitting on top of.
Writing data. I asked both to log an observation. Cloud called add_batch_log and wrote a real row to Postgres (“I have recorded the observation…”). Local bluffed again — “here’s how you can log it yourself.”
Why it matters: capability, not latency
The interesting finding isn’t “the big model is better.” It’s how the small one fails.
With a ~3.8B model on CPU, the bottleneck for agent work isn’t speed — it’s capability. Phi-3.5 couldn’t reliably emit tool calls, so n8n’s tools never fired, and the model degraded into a chatbot that hallucinates a plausible answer instead of fetching the real one. That failure mode is worse than an error: an error you catch, a confident wrong answer you ship.
A couple of measurements that sharpened it:
- NVIDIA 70B, plain chat: ~0.5s.
- NVIDIA 70B, function-calling (with tool schemas): ~8.6s per round-trip — and an agent makes several round-trips per answer. That’s real latency you have to budget a timeout for. (It’s also why the cloud side initially timed out in n8n until I raised the model node’s timeout — the model was fine, n8n was cutting it off.)
So the snappy-vs-slow comparison flips depending on whether the question triggers tools. Plain chat: cloud wins on speed. Tool use: the local model is “fast” only because it skips the tools and makes something up. Speed was never the real axis.
The honest caveat: this is this small general model in a multi-tool agent loop. Purpose-built small models with tool-calling fine-tunes do better at narrow tasks — I run a 1.7B one elsewhere that emits a single structured tool call just fine. But for “pick the right tool from several and chain them,” 70B was in a different league.
The trust boundary
I gave the write tools (add_batch_log, create_batch) to the cloud agent only. The local agent is read-only — not by instruction, by wiring. Even if Phi-3.5 did decide to call a write tool, the connection isn’t there. The reliable model is the only one allowed to mutate real data, and that’s enforced structurally, not by trusting a prompt.
What’s toy and what’s real
Worth being straight: this is a single-node homelab. The agent and both model paths share one box. Running n8n on Kubernetes and swapping models isn’t novel — n8n’s own docs cover queue mode, where a main instance fans work out to a pool of worker pods you scale horizontally, with external Postgres for state. That’s the real production shape. Mine is one replica with an emptyDir’s worth of ambition.
What I think is worth sharing is the finding (the capability cliff, and that its failure mode is confident fabrication) and the boring thing underneath it: because the platform is default-deny and GitOps-reconciled, running this experiment cost me one reviewable egress line and zero risk to anything else.
The boring part is the point
The AI was the fun bit. But the reason I could bolt an agent onto a live cluster, point it at a real app, give it write access to one model and not the other, and tear it all down again — without worrying what it might touch — is that the infrastructure was already boring. Default-deny. Secrets out of Git. git push, Argo reconciles.
The model picks the tools. The platform decides what the tools can reach. Keep those two honest about each other and self-hosting an agent stops being scary and starts being just another app.