A while back I applied for a senior platform role at n8n and didn’t land it. Fair enough — but “fair enough” isn’t actionable. Rejections come with no logs, no metrics, no trace. For someone who runs thirty-odd services with full observability, having vibes as the only instrumentation on my own career felt architecturally embarrassing.
So I built mind-the-gap: a pipeline that measures what the market demands, diffs it against what I can prove, and renders the gap as a private dashboard on my cluster. The job hunt is now a monitored system. This post is about the non-obvious decisions.
Demand: an LLM reads job listings so I don’t have to
I already had a job poller — an n8n workflow that polls the public ATS APIs (Greenhouse / Lever / Ashby) of ~33 companies plus a broad remote-jobs feed every six hours. A sibling workflow now re-fetches the same boards and, for every listing that passes the role+location gate, asks a small hosted LLM (Llama-3.1-8B) for a structured extraction:
{"seniority": "senior", "skills": [{"name": "kubernetes", "importance": "must"}, ...]}
One row per (job, skill) lands in an n8n Data Table. Decisions that mattered:
- One LLM call per job, not one batch. Free-tier inference times out on batches; per-job calls are slower but fail independently. A lesson the poller already paid for.
- Insert doubles as the processed-marker. A job whose extraction fails to parse produces no rows — so it’s retried next run, for free. No status column, no second table.
- Canonicalization in code, not in the prompt. The model says “K8s”, “k3s”, “EKS” on
different days regardless of instructions. A dumb alias map (
k8s→kubernetes,eks→aws) beats prompt engineering for consistency. - 8B is good enough — with a guard. It occasionally echoed the seniority enum back literally
(
"junior|mid|senior|staff|lead|unspecified"). The fix is one line of validation, not a bigger model.
Supply: no artifact, no credit
The other side of the diff is a skills registry — markdown in my knowledge vault, with a
machine-parseable YAML block. Every skill has a state, and the rule that keeps the whole thing
honest is brutal: a skill counts as proven only if an artifact exists — a public repo, a
blog post, documented production experience. Otherwise it’s claimed, and claimed earns half
credit.
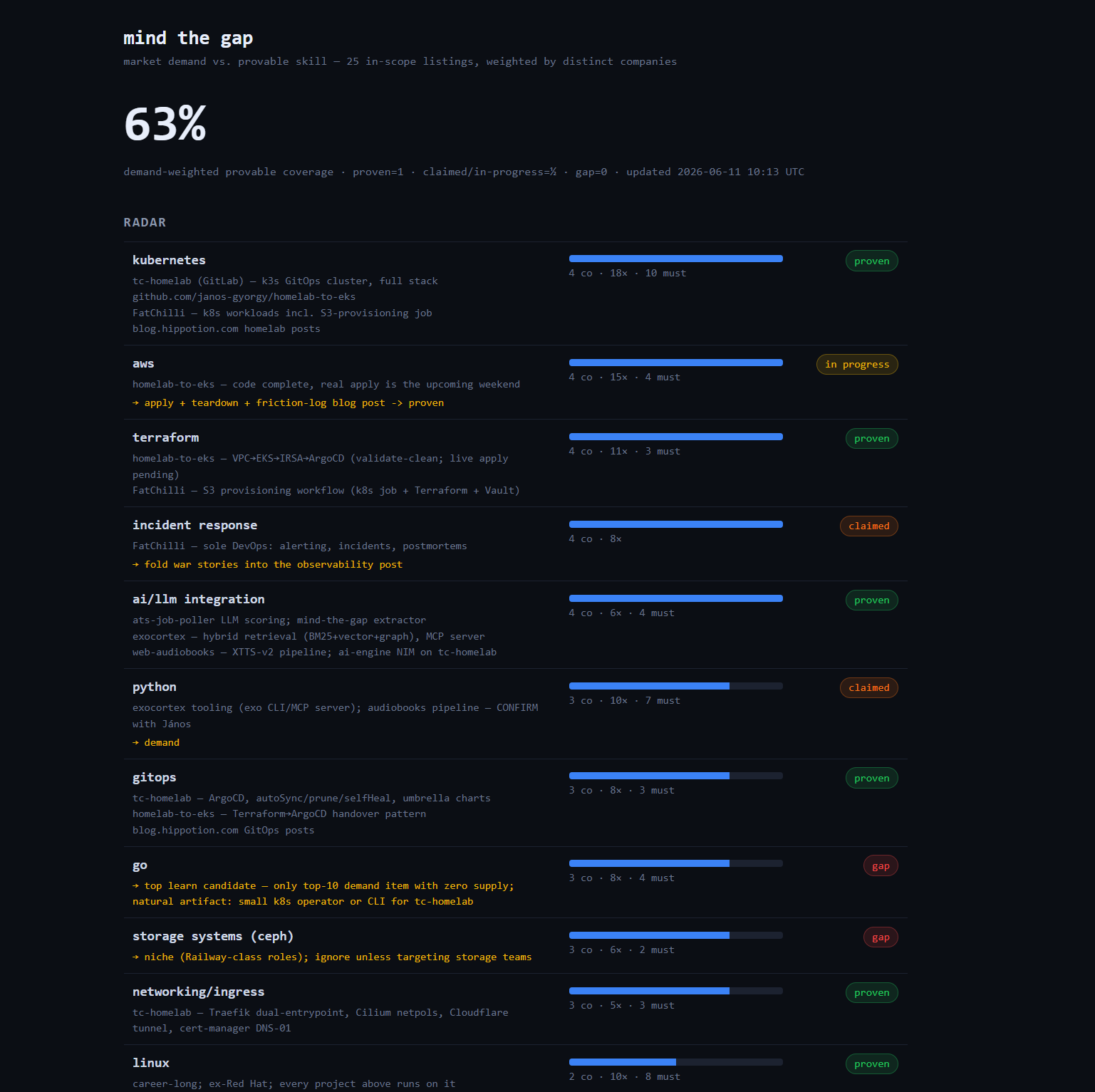
That rule immediately produced the most useful insight of the project: “invisible skill” is a real category. Python turned out to be the market’s #5 ask. I use it constantly — and could point to nothing public that shows it. The cheapest score increase isn’t learning something new; it’s a weekend making an existing skill visible. No gut-feeling gap analysis would have ranked “write about what you already do” above “learn the shiny thing.”
The score: distinct companies, not mentions
First naive aggregation: Canonical’s listings mention Ubuntu nine times, all marked must-have — suddenly Ubuntu looks like the hottest skill in Europe. Employer skew is the noise floor of small samples. The fix: demand weight = distinct companies naming the skill, not total mentions. One enthusiastic employer can’t move the radar.
Two more scoring rules I’d defend in review:
- Skills named by fewer than two companies don’t count at all — single-listing noise stays out.
- Demand the registry hasn’t classified yet shows up as “unreviewed” and counts fully against the score. An unreviewed market signal is a gap until proven otherwise; the dashboard nags me to triage it.
Rendering: the page is a git commit
The dashboard is a single static HTML file, and the pipeline that produces it never touches the
cluster. render.js lives in this repo as the single source of truth; a nightly n8n workflow
fetches it raw from GitLab, eval()s it against the Data Table rows and the registry, and — only
if the result differs from what’s committed (timestamps stripped, or every night is a “change”) —
PUTs the new index.html back via the GitLab API.
Serving is the same pattern as this blog: nginx plus a git-pull sidecar, deployed by Argo CD, behind the cluster’s OAuth middleware. The renderer has no kubeconfig, no SSH, no cluster access of any kind. GitLab stays the only source of truth — even for a page that rewrites itself nightly. If the workflow goes rogue, the worst it can do is a reviewable commit.
Day-one verdict
First run: 2,297 postings fetched, 25 in scope, 257 skill rows. Coverage score: 63%. Kubernetes and AWS tied at the top of demand — which means the AWS gap-closing project already in flight stopped being a hunch and became the measured top of the market. Go is the only top-ten demand with zero supply. The dashboard doesn’t get anyone a job; it just makes sure every learning Saturday is pointed where the data says, not where the hype does.
The job board rejected me. The data didn’t.
Workflows, render.js, and setup: github.com/janos-gyorgy/mind-the-gap.