You don’t have to be about to change jobs to want to know the landscape. What’s being built, what it pays, where you’d actually fit — staying current on the market (and your own worth) is just good professional hygiene. The trouble is that checking is tedious, so most of us don’t, until we’re already job-hunting and starting cold.
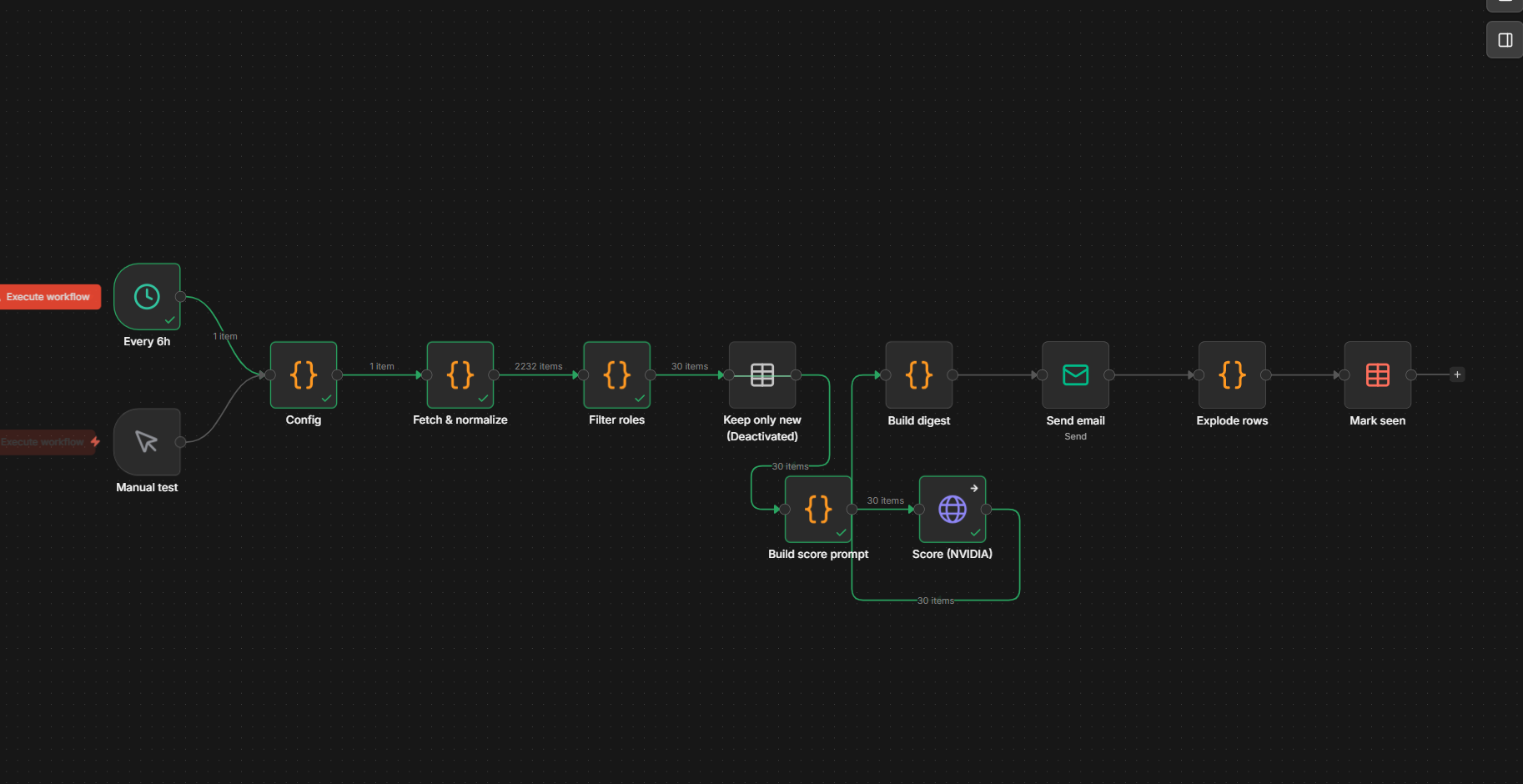
So I automated mine. An n8n workflow on my homelab polls job boards every six hours, scores each new posting against my profile with an LLM, and emails me only the strong matches — the ones scoring 80%+. When it’s quiet, it’s silent. When something genuinely fits, I know the same day. Here’s what I learned building it. Repo at the bottom.
Three APIs cover most of the market
Company career pages look bespoke, but underneath, the vast majority run on one of three ATS — and all three hand you the jobs as unauthenticated JSON:
- Greenhouse —
boards-api.greenhouse.io/v1/boards/{token}/jobs?content=true - Lever —
api.lever.co/v0/postings/{token}?mode=json - Ashby —
api.ashbyhq.com/posting-api/job-board/{token}?includeCompensation=true
No scraping, no headless browser. You poll the API the page itself calls, normalize the three
shapes into one { company, title, location, remote, url, posted_at, description, external_id }, and
you’re done with the hard part.
“Resolve the token” is half the battle
The naive assumption — the token is the company name, and everyone’s on one of the three — is half right. When I probed my initial wishlist, roughly half 404’d everywhere: HashiCorp (now under IBM → Workday), SUSE (SuccessFactors), Aiven (Teamtailor), Hugging Face. They’re on a fourth or fifth system entirely. The honest move was to ship the ~33 that actually resolve and leave the rest as disabled config stubs. Verify before you trust a slug.
Dedup without a database
I didn’t want to stand up Postgres just to remember which jobs I’d already seen. n8n’s Data Tables
handle it natively: a seen_jobs table, an external_id namespaced {ats}:{company}:{id}, and the
rowNotExists operation drops anything already recorded. State lives inside n8n, backed up with it.
Zero extra infrastructure.
The ordering matters: notify first, mark seen second. The insert only happens after the email sends, so a failed send retries next run instead of silently swallowing a posting.
The location filter is a trap
My first version kept everything that wasn’t explicitly US-based. The inbox filled with “Senior Platform Engineer — Spain (Remote)” and "… — United Kingdom (Remote)". Those aren’t remote-for-me — they’re remote if you live in Spain. Useless from where I sit.
The fix was to invert the logic. Keep only three things:
- globally-remote / worldwide / anywhere,
- pan-EU (EMEA / Europe / EU / EEA),
- my own country.
…and drop single-country remote, even EU ones. Region and home matches win over the country deny-list, ambiguous locations are kept (a missed match is worse than one extra line to skim). That one change cut the noise more than anything else.
Let an LLM read the actual job
Keyword + location filtering gets you a candidate list, but it can’t tell a “Platform Engineer” who herds Kubernetes from a “Platform Engineer” who owns a Figma design system. The job description can.
So the last step scores each new posting against my CV. My first version batched all of them into one big LLM call — which promptly timed out on the free tier. The fix was the opposite: one small call per job, which also means a single slow or rate-limited job never sinks the batch. Each call asks a NVIDIA NIM model (Llama 3.1 8B, OpenAI-compatible) for one number and a reason:
Score this job 0–100 for fit against my profile. Return
{score, reason}.
That score is what lets me widen the net instead of narrowing it. On top of the curated company list I pull a broad remote-jobs feed (every company, all categories); the cheap keyword + location filters do the first pass, then I only email the roles scoring 80%+. Casting wide is fine when a model is the bar at the door. A line ends up looking like:
92% — Grafana Labs — Senior Platform Engineer (Remote, EMEA) — strong k8s/GitOps overlap — link
Scoring is fail-safe: if a call hiccups, that job is just skipped, and every posting gets marked seen either way — so nothing re-scores forever, and a rare bad run never floods or stalls the inbox.
The unglamorous bits that make it trustworthy
- One bad source can’t kill the run — every fetch is wrapped; failures become a
⚠️ N sources failingfooter so a company quietly changing ATS is visible, not invisible. - A prime run seeds the table silently the first time, so I’m not buried under every currently-open role on day one.
- Everything tunable lives in one Config node — companies, keywords, location lists, the profile, the model — so adding a company is a one-line edit, not a graph safari.
Takeaways
- The “scrape job boards” problem mostly isn’t a scraping problem — it’s three public APIs and a normalizer.
- For personal automation, reach for the boring-but-correct primitive: native dedup state beats a database you have to operate.
- An LLM works best here as the bar at the door: cheap deterministic filters keep the candidate set (and the cost) small, then the model gates on real fit — which is what lets you cast a wide net without drowning in it.
Workflow JSON, the full node-by-node breakdown, and setup notes: github.com/janos-gyorgy/ats-job-poller.